Ok, I have a partial understanding. What you have called ‘filter for records’ would be a query to count cases in an original data category (SOPClassUID in this case). It can be adjusted for different filters by changing the ‘WHERE Clause’. Now ‘filter for counts’ would be a query to count cases in derived:segmentation categories (but replace SOPClassUID with a derived:segmentation category). The only difference between this and ‘filter for records’ (besides the category) is the ‘has_segmentation=true’ clause. I think for counts in derived:quantitative you have ‘has_quantitative=true’ instead? Now ‘has_segmentation=true’ is only going to matter when ‘AnatomicRegionSequence is NULL’ is in the filter. If AnatomicRegionSequence has any other filter value then ‘has_segmentation=true’ is redundant.
Actually I I can take a stab at explaining it … with set theory and Venn diagrams. It can be understandable but as is the numbers are not going to be intuitive to anyone who has not spend a few minutes with the documentation.
Example w Discussion:
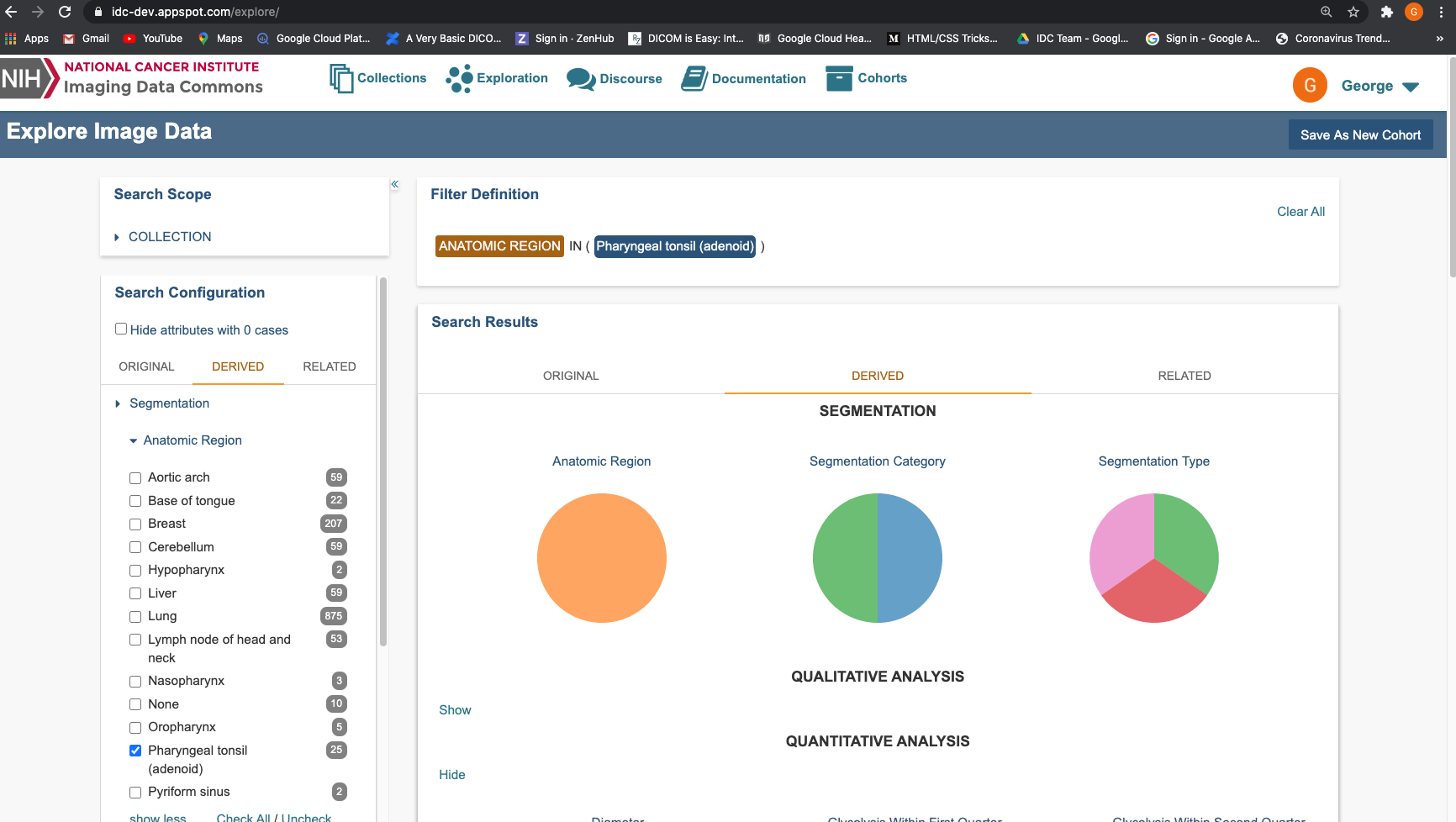
Here we filter for Atomic Region=Pharyngeal tonsil (adenoid)). From the UI there should only be 25 cases selected.

Here we examine the Modality Counts for the filter ‘Atomic Region=Pharyngeal tonsil (adenoid))’ (see RHS). Each case can have multiple modalities, so we do not expect the sum of all counts to be equal to 25, but the maximum number of counts in any one attribute to be less or equal to 25. This is confirmed.

Here we filter for ‘Atomic Region = None’. The UI is showing that there are only 10 cases with ‘Atomic Region = None’. However, within the Anatomic Region category the UI is only counting cases which have segmentation data but do not have an Anatomic Region within the segmentation data as None. There are hundreds of other cases that do not have any segmentation data.

Here is Modality with the filter ‘Anatomic Region=None’. How is it that many of the case counts are much greater than 10, the total number of cases we show for the ‘Anatomic Region=None’ bucket? Well in counting cases for Modality we now include all the cases that do not have any segmentation data, and by default their ‘Anatomic Region’ is None.
Thank you George, this is precisely what’s happening.
Again–it doesn’t have to work this way, this is just the logical outcome of wanting to associate derived data with the studies/cases they’re linked to. Because we’re working at an instance level with our data, where the derived and original records of a given study or case aren’t unified in one another’s attribute values (because why would they be–they’re different records, after all), we get some weird numbers and lists when we want to count on something other than instance records.
This is is why Ulrika and Justin asked us what we planned to do; it’s a thorny problem with no obvious answer, beyond ‘decide and document’.
Well, not quite - in fact we include all of the cases that have any instance with ‘Anatomic Region’ set to None. And every single case will have such instance, since every single study that has a Segmentation instance will have non-Segmentation instances.
So if the user selects ‘None’ for Derived filters, it has no effect on the definition of the cohort. I do not know how this can be helpful. We can discuss how this behavior can be improved, but until then maybe it’s better to just remove “None” as an option from the filters.
Following the discussion today with @spaquett, @george.white and @wlongabaugh, we all agreed to disable “None” filter selection for the derived data, since its current behavior is most likely not what any user would expect.